In Computer-Science, there are certain problems that don't always adapt to code easily.
The classic Uni-Directional Path-Tracing (UDPT) is fairly simple to solve. However, we'll see later that Bi-Directional Path-Tracing (BDPT) is quite a bit more involved.
As long as you trace from the sensor towards the light-source, you're talking about an algorithm
that could take less than 30 lines of code to implement.
I'm simplifying a lot here, since in reality there would need to be a framework for casting rays
and for defining the scene that those rays intersect.
But still, it's a fairly straight-forward solution.
What I described above is normally referred to as "Eye-Tracing", which is the exact opposite of
how light rays propagate in reality.
We refer to its counterpart as "Light-Tracing" which as the name suggests,
starts at the light-source and traces towards the sensor.
Light-Tracing requires a bit more planning of how you model your camera (ie: lens, aperture type, and viewing film), but is still relatively simple to implement.
Eye-Tracing is mostly efficient at sampling wide-area lights and open scenes, whereas Light-Tracing is more
efficient at sampling tiny lights and also heavily confined/convoluted scenes.
Additionally, Eye-Tracing is nearly incapable of sampling caustics like from glass or mirrors. For that
reason, we may prefer to use Light-Tracing for those cases.
The problems start when you try combining these two algorithms together with Bi-Directional
Path-Tracing; and then, if you use the more efficient variant, it's called:
Bi-Directional Path-Tracing with Multiple-Importance Sampling (BDPT with MIS).
Whew! That's quite the title for such an important computer-graphics algorithm.
Luckily for us, most people refer to BDPT with MIS as just BDPT since it's hardly used without MIS.
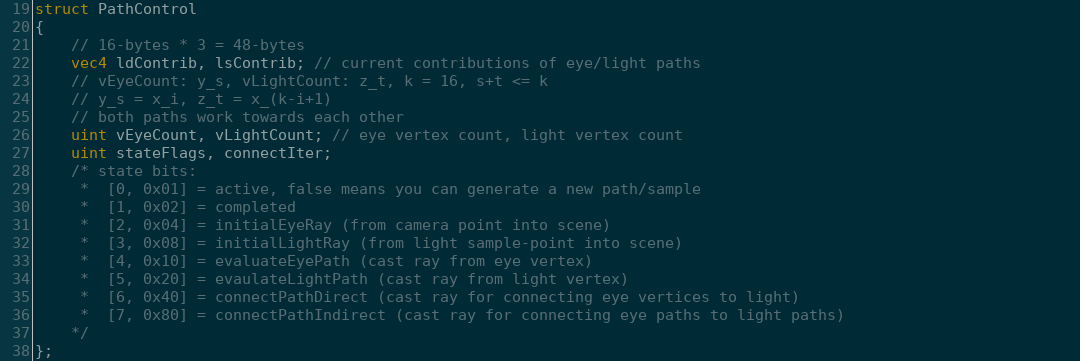
The first term "Bi-Directional" basically means we're tracing rays from both the sensor
and the light-source to produce a path.
The second term "Multiple-Importance Sampling" is a method that chooses the best algorithm from many
possible candidates.
If we consider a single sample in a naive BDPT, we would shoot an eye-ray into the scene,
bounce around until a condition is met, and then repeat those steps but from a light-source instead.
After both eye- and light-paths are created, we complete the sample by merging them.
This is done by shooting "connection" or "shadow" rays between each vertex in the eye- and light- paths.
Once all eye-vertices have been connected to every light-vertex, then the sample is complete. We repeat
these steps for the rest of the image.
At this point, BDPT may sound quite complicated, but it can be further broken down into smaller problems.
We can treat each of the eye-to-light path connections as if an eye-path was sampling a light-source.
In this case, however, the lights are substituted with light-vertices instead, which contain the
required information of their contribution to the sample.
There's a problem here though; with plain BDPT we could have eye- and light- paths with dozens
(if not hundreds) of bounces! If we don't choose to place an arbitrary limit on the number of bounces,
we end up with an exponential growth of connection rays!
How can we prevent this? The answer is MIS, which if used properly, not only fixes our complexity problem,
but also produces a similar result in much less time.
As previously stated, MIS is a way of combining sampling techniques, but by what means?
Multiple-Importance Sampling was a concept discovered by Eric Veach and
Leonidas Guibas in their '95 paper:
Optimally Combining Sampling Techniques for Monte Carlo Rendering.
Veach later expanded on this class of algorithm in his '97 thesis paper:
Robust Monte Carlo Methods for Light Transport Simulation.
In his thesis he explained different use cases for this "adaptive" multi-sampler.
The simplest approach to MIS is to take multiple functions (ie: light-sampling methods), and calculate the
contribution each would make if they were to succeed. For each function, you would store it's
output as a weight, and then accumulate that weight to a running total.
After all the sampler values are computed, you normalize them by dividing each by the sum of their weights.
The actual sampling consists of selecting which rays will actually be cast by comparing each
corresponding weight against a random number (between 0 and 1).
This results in lower contribution samples being "culled" out, while following through with brighter samples.
Additionally each iteration contributes less to the scene, but also takes considerably less time
to compute as well.
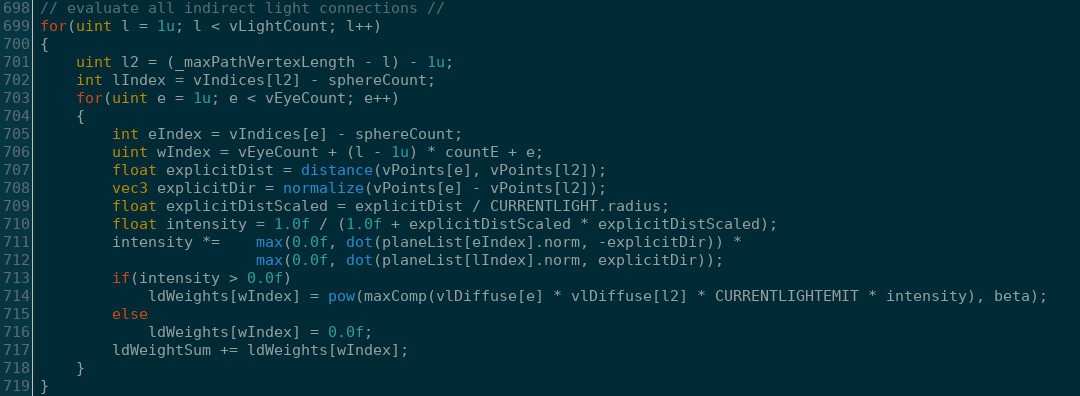
But how do we apply this to BDPT? Well, we just calculate all the ways that every eye-vertex could connect to each
light-vertex and sum their weights. Then we take the normalized weights and test them against our random
number generator to decide which connection paths are chosen.
If a connection is unoccluded, we add the appropriate contribution of that path divided by the probability
of choosing that connection.
Using this method, we reduce our complexity greatly as the path length increases.